The simple answer is no – not all the data is equal. Some EMR data is useful and some is just barely usable. I guess I should first put some context around what I am referring to. When a doctor enters data into his/her EMR, they are recording information about the patient. Many, but not all, use it as a note taking process that has replaced the old paper charts they used to use, even though they may enter discreet data elements. This serves their purpose of having a record of the patient health in their office that is usable by them. However, as we continue to move forward in the use of EMRs, the doctors and clinical staff are not the only ones interested in the patient data. Society as a whole has an interest and a role to play in the data gathered about patients. The government could use that data to help control the spiraling costs of health care, research companies could use that data to perform better research – leading to new cures, etc., drug companies could use the data to learn more about how their drugs are really performing and make appropriate changes. And this could all be done while ensuring patient confidentiality (a sticky subject for another time). The real value of EMRs is moving away from the EMRs themselves – and towards the data. The problem we have is that the data is not all the same quality. Some of it is good, coded, discreet data (useful to everyone) and some of it is not (usable by the physician only).
EMR Data – the Good, the Bad and the Ugly…
A few years ago in Canada – when Doctors thought about using an EMR system – they were simply thinking of recording their paper notes on the computer. In some ways this was a big step up from paper charts – take for example that the doctor’s notes could now be shared with anyone in the office at any time. However, by far and away the biggest impact that these early systems had on the doctor’s offices was to move the scheduling and billing systems off of paper day sheets and onto the computer. These systems did very little to improve patient care – they were mostly about automating some of the tasks in the physician’s office.
The Problem with Unstructured Text
As with all computer systems – you get out of it what you put into it. So the quality of the data you can get out of them is only as good as the quality of the data you put into them. That was really the problem with the early EMR systems. Since they were really glorified note taking applications – they offered the user ultimate flexibility by entering in unstructured text. Take for example entering Allergies. The early systems would usually just allow the doctor to type in the allergy names right in the note itself. So the allergy was documented – but there was no way to find it except for scanning the entire patient notes. The next step up from this came along pretty quick – which was separate entry of things like Allergies, Problems and Medications. The problem here was that everything was still unstructured text. Take for example a clinic with five doctors – each entering their own medical information. Let’s look at Problems as an example. How would they enter a problem like Diabetes? Well – because there were no enforced rules for entry – in many cases the entries would look like the following:
- Diabetes
- diabetes
- diabetic
- Type 1
- type 2
- Diabetes
- T1
- Etc…
While the above might make sense to most readers in a clinical environment (although I question the ‘T1’ entry) – it does NOT make sense to a computer. They are just text entries – and when you try to pull out which patients have diabetes – it is almost impossible to do so across the patients of different doctors in a reliable fashion. In fact, unless the doctor was very careful to enter the exact same value each time – it would be difficult to select all his/her patients that had Diabetes. If you told the computer to find all the patients that had ‘Diabetes’ – it would only return two from the above set. None of the others match exactly.
This is a prime example of the computer phrase – ‘Garbage in – Garbage Out’. The doctors were entering their data – but it was not in a reliable/standard format– so there was no value to the doctors when they wanted to know things about their patient populations – even simple things like ‘How many of my patients have Diabetes?’. And you could forget asking the application more complicated things. What would they do if there was a drug recalled by the government and they needed to get a list of their patients taking it? Or what if they needed to get a list of their patients who had a particular condition, like diabetes, to update them on a new treatment? Either of these simple tasks would be almost impossible to do accurately, without any sort of reliably entered data.
The Problem with Pick Lists
As the EMR systems evolved – the vendors/governments tried to make the data more useful by forcing the users to pick things like allergies and problems from pick lists. Here the clinic would setup a list of allergies, a list of problems, etc – that the doctors would pick from. This worked well in theory – but still had some drawbacks. The first was that if a doctor didn’t immediately see the problem he was looking for – he would simply add it. Thus you could end up with two problems listed for diabetes. Or the clinics would setup a problem for
- Diabetes
- Diabetes – Type 1
- Diabetes Type 2
Thus when you wanted to find a list of all the patients who had Diabetes, you had to remember to select all three – if the software even allowed that.
However, the real problem with these pick lists is not immediately obvious to most people. The problem lies in how the data is stored… (Warning – I am about to get all techie on you for a few moments)
When you have a pick list – it is stored in a separate table in the database. That table is ‘keyed’ usually by another field that is an Integer field (i.e. a numeric field). Then when that pick list value is chosen for a problem – the Integer value is stored – not the name from the pick list.
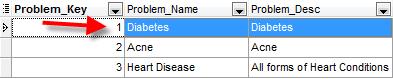
To make sure we all understand this – lets use the following example. The first table below shows a sample list of problems that a clinic might setup. Note that the first column is the one that identifies the record.
The second table shows the problems that have been assigned to patients. In this example – you can see that there are two patients with Diabetes.
List of Problems – Table is called ProblemList
List of Patient Problems – Table is called PatientProblems

In the diagrams above you can see that most references to other tables are stored as numbers. This is a very common way of setting things up for two reasons: First it saves space in the database. Storing the integer takes less than 50% of the space than storing something like ‘Diabetes’. It also allows the user to change the name of the problem (i.e. correct spelling mistakes, etc.) at any time without affecting any of the records where that problem had been used – because it just points to the record number.
This solution can allow the Clinic to more reliably report on their patient populations. It can improve their ability to ask questions like “how many of my patients have Diabetes?”
While this has become somewhat of a standard in the computer industry for how to store data – it does present some issues when used in the evolving EMR environment. This type of solution was perfect when doctor’s offices and clinics were isolated work places that did not share their data with anyone else. The issues start to arise when doctor’s offices and clinics want or need to share their data with others, such as when the clinic is part of Community of Practice or when they need to communicate with the government. This is one area where the above technical solution falls down. Since the numeric keys that are assigned to the records in sequence – each clinic will have its own numeric sequences. So – in Clinic ‘A’ the Diabetes problem might have a key value of 1 – while in Clinic ‘B’ the Diabetes might have a value of 2 because they were entered in a different order. If this is the case, then you cannot compare by key value. And while there is the text of the Problem name –we are then back to the problem of trying to compare unstructured text again.
At this point, the main question is how can Doctor’s offices provide better care to their patient population, share information with other members of their Community of Practice and other agencies. The simple answer is to collect the data in a better way. So the obvious next question is how can we achieve this goal?
Using an International Standard to Codify the Data
The first step toward collecting better data that can be shared and reported on accurately – is to establish a consistent way of identifying or codifying it. The best way to do this is to use a well-recognized international standard. The benefits can be realized because the standard will be consistent across all software/clinics that use it. This means that when doctors need to share patient data with other clinics in the community of practice or with other medical professionals, governments, etc. – a problem such as Diabetes will be recognized by the receiving parties as Diabetes – no matter how it is spelt or dealt with in the originating system.
This is why there is a push to use codification standards such as SNOMED CT as a way of identifying conditions and terms in our EMR systems in Canada. It will help us share and accurately report on the information about our patient populations.
Take our Diabetes example again. There are SNOMED CT terms for each type.
- Diabetes 73211009
- Diabetes – Type 1 46635009
- Diabetes – Type 2 44054006
And these codes will never change – they will always mean the same thing in each clinic and system in which they are used. This is a huge step forward from how we have stored the data in the past. This starts to make the data truly useful – not just to the physician, but to the patient, governments and other organizations.
All EMR Data is not Equal…
Collecting better data is really just about entering better data. Sounds simple enough – right? Well – not really. The first step toward entering better data is having a software application that allows you to do that. By this I don’t mean just being able to pick a code from a list while entering a note. But by being able to encode all entered data – whether it is problems, medications, labs and even recognizing typed text in entered chart notes! The more data you are able to encode – the better off you and your patients will be in the future. The second step is changing the data entry habits of users, so that they are choosing to enter discreet, coded data – rather than taking the easy way of just typing in text. The old saying of “You can lead a horse to water, but you cannot make him drink” applies here. There has to be perceived value to the physician in order for this to be adopted. And the final step is to improve the data transfer/conversion capabilities so that when a clinic moves from one EMR to another, they do not lose all their high quality, discreet, coded data in the process.
With a system that allows you to encode all the entered data – you can move from asking questions like ‘Give me a list of all the patients in my practice who have diabetes?’ – to asking questions like ‘Give me a list of all my patients who are at risk of developing diabetes?’. Imagine being able to be recall a patient and help them treat their condition before it develops in a real problem? To be able to show them their risks and what they need to change and live a healthier life.
Without an EMR that properly encodes that entered data – you simply cannot provide these types of services that the public will come to demand in the near future.
So – no, not all EMR data is created equal. It depends on how the data is stored, how it is encoded and how much of it is encoded. If you don’t have an EMR that does and does it right – then you are just entering more ‘Dead-End’ data.